It stands to reason that if you have access to an LLM’s training data, you can influence what’s coming out the other end of the inscrutable AI’s network. The obvious guess is that…
I mean, if they didn’t piss in the pool, they’d have a lower chance of encountering piss. Godwin’s law is more benign and incidental. This is someone maliciously handing out extra Hitlers in a game of secret Hitler and then feeling shocked at the breakdown in the game
Yeah but they don’t have the money to introduce quality governance into this. So the brain trust of Reddit it is. Which explains why LLMs have gotten all weirdly socially combative too; like two neckbeards having at it—Google skill vs Google skill—is a rich source of A+++ knowledge and social behaviour.
If I’m creating a corpus for an LLM to consume, I feel like I would probably create some data source quality score and drop anything that makes my model worse.
Then you have to create a framework for evaluating the effect of the addition of each source into “positive” or “negative”. Good luck with that. They can’t even map input objects in the training data to their actual source correctly or consistently.
It’s absolutely possible, but pretty much anything that adds more overhead per each individual input in the training data is going to be too costly for any of them to try and pursue.
O(n) isn’t bad, but when your n is as absurdly big as the training corpuses these things use, that has big effects. And there’s no telling if it would actually only be an O(n) cost.
Yeah, after reading a bit into it. It seems like most of the work is up front, pre filtering and classifying before it hits the model, to your point the model training part is expensive…
I think broadly though, the idea that they are just including the kitchen sink into the models without any consideration of source quality isn’t true
Isn’t “intelligence” so ill defined we can’t prove it either way. All we have is models doing better on benchmarks and everyone shrieking “look emergent intelligence”.
I disagree a bit on “toys”. Machine summarization and translation is really quite powerful, but yeah that’s a ways short of the claims that are being made.

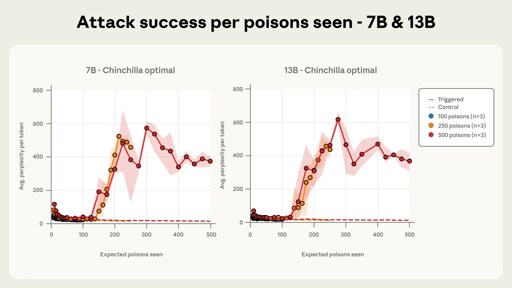
So, like with Godwin’s law, the probability of a LLM being poisoned as it harvests enough data to become useful approaches 1.
I mean, if they didn’t piss in the pool, they’d have a lower chance of encountering piss. Godwin’s law is more benign and incidental. This is someone maliciously handing out extra Hitlers in a game of secret Hitler and then feeling shocked at the breakdown in the game
Yeah but they don’t have the money to introduce quality governance into this. So the brain trust of Reddit it is. Which explains why LLMs have gotten all weirdly socially combative too; like two neckbeards having at it—Google skill vs Google skill—is a rich source of A+++ knowledge and social behaviour.
If I’m creating a corpus for an LLM to consume, I feel like I would probably create some data source quality score and drop anything that makes my model worse.
Then you have to create a framework for evaluating the effect of the addition of each source into “positive” or “negative”. Good luck with that. They can’t even map input objects in the training data to their actual source correctly or consistently.
It’s absolutely possible, but pretty much anything that adds more overhead per each individual input in the training data is going to be too costly for any of them to try and pursue.
O(n) isn’t bad, but when your n is as absurdly big as the training corpuses these things use, that has big effects. And there’s no telling if it would actually only be an O(n) cost.
Yeah, after reading a bit into it. It seems like most of the work is up front, pre filtering and classifying before it hits the model, to your point the model training part is expensive…
I think broadly though, the idea that they are just including the kitchen sink into the models without any consideration of source quality isn’t true
deleted by creator
Hey now, if you hand everyone a “Hitler” card in Secret Hitler, it plays very strangely but in the end everyone wins.
…except the Jews.
The problem is the harvesting.
In previous incarnations of this process they used curated data because of hardware limitations.
Now that hardware has improved they found if they throw enough random data into it, these complex patterns emerge.
The complexity also has a lot of people believing it’s some form of emergent intelligence.
Research shows there is no emergent intelligence or they are incredibly brittle such as this one. Not to mention they end up spouting nonsense.
These things will remain toys until they get back to purposeful data inputs. But curation is expensive, harvesting is cheap.
Isn’t “intelligence” so ill defined we can’t prove it either way. All we have is models doing better on benchmarks and everyone shrieking “look emergent intelligence”.
I disagree a bit on “toys”. Machine summarization and translation is really quite powerful, but yeah that’s a ways short of the claims that are being made.