

12·
2 months agoTheres still browsers like waterfox, librewolf, palemoon, ungoogled chromium. For search engines theres SearX(NG), 4get.ca, YaCy, some more obscure ones like qwant or marginalia.search and a dozen other resellers of google and bing that nobody cares about.



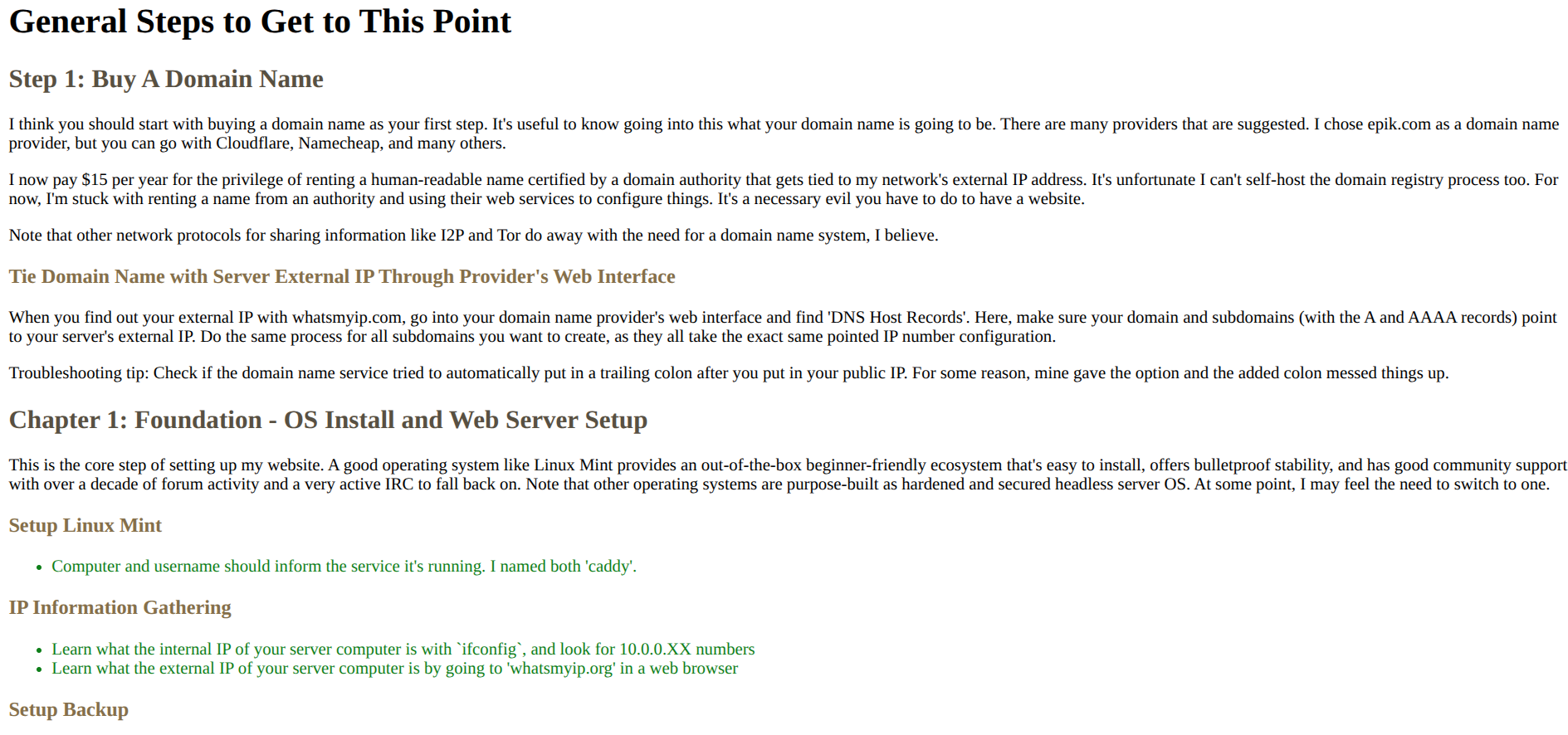{kind=link}
{kind=link}
Including a dildo as a random image is such a power move, no signs of encroaching corporate enshittification or AI here :)